
Архитектурный разбор GPU Moore Threads MTT S4000
12 марта 2026 г.
В последние годы на рынке высокопроизводительных вычислений и искусственного интеллекта сложилась парадоксальная ситуация. С одной стороны, гегемония NVIDIA с ее экосистемой CUDA кажется незыблемой. Десятилетия инвестиций в исследования, разработку и создание обширной экосистемы, включающей библиотеки, фреймворки, инструменты отладки и огромное сообщество разработчиков, сделали CUDA золотым стандартом для GPGPU вычислений. Продукты, такие как Tesla V100, A100 и новейшие H100, стали отраслевым стандартом де-факто, а их архитектурные инновации, включая тензорные ядра, задавали темп развития всей индустрии.
С другой стороны, для многих российских компаний санкционные ограничения и проблемы с логистикой сделали доступ к новейшим ускорителям (таким как H100/A100) либо невозможным, либо экономически нецелесообразным. Цены на флагманские ускорители NVIDIA в российской рознице достигают нескольких миллионов рублей за карту, что делает построение и масштабирование AI инфраструктуры неподъемным для многих компаний, особенно для стартапов и среднего бизнеса. Этот вакуум неизбежно начал заполняться, и самые амбициозные претенденты пришли из Китая.
Сегодня мы не будем говорить о «еще одном аналоге». Мы препарируем, пожалуй, самое интересное с инженерной точки зрения решение - серверный ускоритель Moore Threads MTT S4000. Интересен он не столько голыми терафлопсами, сколько подходом его создателей, которые не просто скопировали чип, а попытались воссоздать всю экосистему, от архитектуры до программного стека. Это стратегически важный момент: успех в AI вычислениях сегодня определяется не только мощностью «железа», но и зрелостью, полнотой и удобством программной обвязки. Давайте без предвзятости разберемся, что представляет собой этот «китайский дракон» на архитектурном уровне, и насколько он готов к реальным боевым задачам.
Декларация о намерениях: Что нам обещают на бумаге и что это значит
Для начала - сухие факты. Чтобы понимать, с чем мы имеем дело, сведем ключевые заявленные характеристики MTT S4000 и сравним их с NVIDIA A100 80GB PCIe, используя данные из официального даташита.
Параметр | Moore Threads MTT S4000 | NVIDIA A100 80GB PCIe | Контекст и значение для AI/HPC |
Архитектура | MUSA (3-е поколение, QuYuan) | Ampere | Собственная унифицированная архитектура. Ключевой фактор для программной совместимости и оптимизации. |
GPU | Chunxiao | GA100 | Кодовое название чипа. |
Техпроцесс | 12 нм | 7 нм | Зрелый, доступный техпроцесс для MTT S4000. Современный и энергоэффективный для A100. |
Транзисторы | 22 млрд | 54.2 млрд | Высокая плотность транзисторов, указывающая на сложность и вычислительную мощь чипа. |
Вычислительные блоки | 8192 ядер MUSA | 6912 ядер CUDA | Общее количество исполнительных блоков. |
Тензорные ядра | 128 (нового поколения) | 432 | Специализированные блоки для ускорения матричных операций (основа нейросетей). |
Производительность FP64 | - | 9.7 TFLOPS | Производительность с плавающей запятой двойной точности. Важно для HPC. |
Производительность FP64 Tensor Core | - | 19.5 TFLOPS | Ускорение двойной точности с помощью тензорных ядер. |
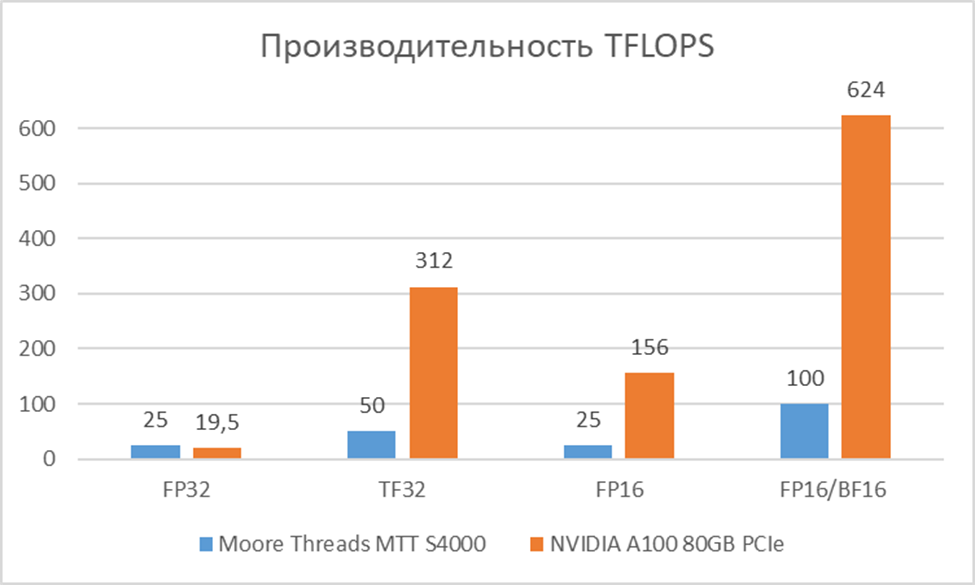
Производительность FP32 | 25 TFLOPS | 19.5 TFLOPS | Пиковая производительность в операциях с плавающей запятой одинарной точности. MTT S4000 показывает превосходство в FP32. |
Производительность TF32 Tensor Core | 50 TFLOPS | 312 TFLOPS* | Производительность в формате TensorFloat32. A100 значительно превосходит MTT S4000. |
Производительность FP16 | 25 TFLOPS | - | Базовая производительность FP16. |
Производительность FP16/BF16 Tensor Core | 100 TFLOPS | 624 TFLOPS* | Производительность в операциях с плавающей запятой половинной точности с использованием тензорных ядер. A100 значительно превосходит MTT S4000. Критично для обучения большинства современных нейросетей. |
Производительность INT8 Tensor Core | 200 TOPS | 1248 TOPS* | Производительность в целочисленных операциях. A100 значительно превосходит MTT S4000. Ключевой показатель для инференса. |
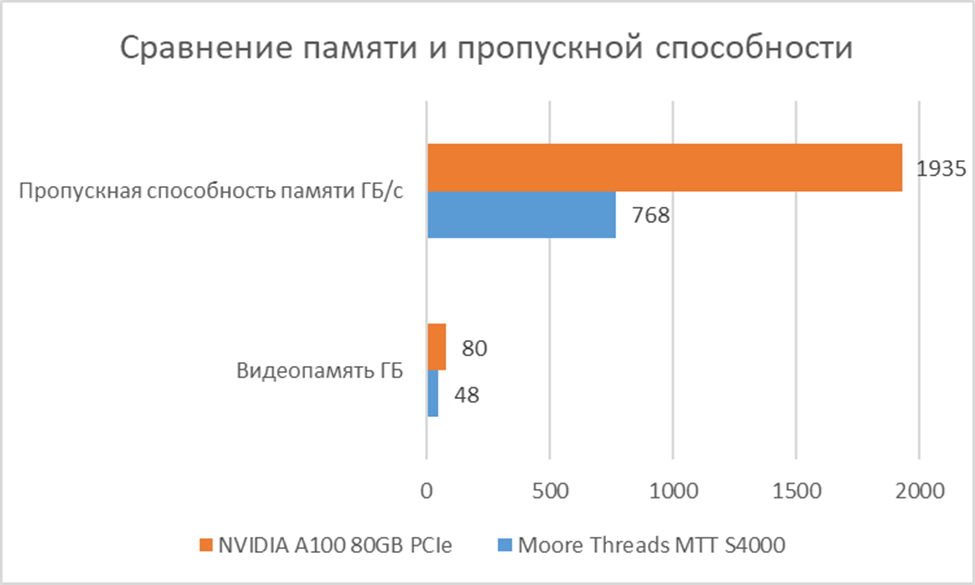
Видеопамять | 48 ГБ GDDR6 | 80 ГБ HBM2e | Объем памяти. Важен для больших моделей и батчей. HBM2e у A100 обеспечивает значительно более высокую пропускную способность. |
Пропускная способность памяти | 768 ГБ/с | 1935 ГБ/с | Скорость доступа к видеопамяти. Критично для производительности, особенно для моделей с большим количеством параметров. A100 имеет почти в 2.5 раза выше. |
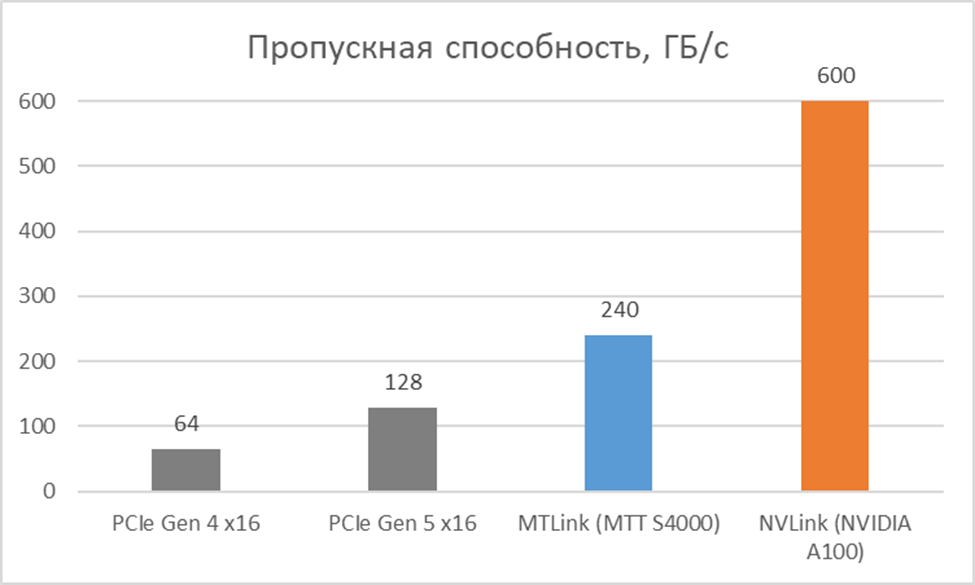
Интерфейс PCIe | PCIe 5.0 x16 (128 ГБ/с) | PCIe Gen 4 x16 (64 ГБ/с) | Стандарт подключения к материнской плате. PCIe 5.0 у MTT S4000 обеспечивает более высокую базовую скорость. |
Интерконнект | MTLink (240 ГБ/с, MTLinkLO 112 ГБ/с) | NVLink (600 ГБ/с) | Собственный высокоскоростной интерконнект для связи между несколькими GPU. NVLink у A100 значительно быстрее. |
Декодеры | 48x1080p@30fps (AV1, H.264, H.265); 96x1080p@30fps (AV1, H.264, H.265, VP9, AVS2) | - | Аппаратное ускорение видео. Критично для видеоаналитики и стриминга. |
Кодировщики | 48x1080p@30fps (AV1, H.264, H.265) | - | Аппаратное ускорение кодирования видео. |
Рендеринг | Текстурирование: 768 Гтекселей/с, Пиксели: 768 Гпикселей/с | - | Важно для графики, цифровых двойников и метавселенных. |
TDP | 450 Вт | 400 Вт | Максимальное тепловыделение. A100 значительно более энергоэффективен. |
Display | 4x DP1.4a | - | Поддержка вывода изображения. |
Форм-фактор | PCIe, двухслотовый, 266x112x39 мм | PCIe, двухслотовый или однослотовый с ЖО | Физические размеры и тип подключения. |
Безопасность | MUSA Safety Engine 2.0, TEE | - | Аппаратные функции безопасности. |
Виртуализация | Динамическое разделение, SR-IOV | MIG (Multi-Instance GPU) | Возможности виртуализации GPU для эффективного распределения ресурсов. |
* С использованием структурной разреженности (Sparsity)
Первое, что бросается в глаза - это не попытка сделать дешевую затычку, а вполне серьезная заявка на современный серверный ускоритель. Объем памяти в 48 ГБ и пропускная способность в 768 ГБ/с ставят его в один ряд с NVIDIA A100 (которая имеет 80 ГБ VRAM), демонстрируя серьезную заявку на конкуренцию, особенно учитывая значительное превосходство MTT S4000 в FP32. Поддержка PCIe 5.0 и наличие собственного интерконнекта MTLink говорят о том, что инженеры Moore Threads мыслили категориями современных AI-кластеров, где масштабируемость и высокая пропускная способность между компонентами критически важны.
Для наглядного сравнения ключевых характеристик MTT S4000 и NVIDIA A100 80GB PCIe, предлагаем ознакомиться с инфографикой.
Однако дьявол, как всегда, в деталях. И главная деталь здесь 12-нм техпроцесс у MTT S4000 против 7-нм у A100. Это зрелая и, вероятно, более доступная в производстве технология для Moore Threads по сравнению с 7-нм техпроцессом TSMC, на котором построен A100. Выбор такого техпроцесса является не технической слабостью, а осознанным стратегическим решением. Для компании, находящейся под экспортными ограничениями и стремящейся к технологической независимости, доступ к передовым производственным мощностям затруднен. Поэтому ставка на проверенный 12-нм узел - это способ обеспечить серийное производство, предсказуемость поставок и, что немаловажно, снизить себестоимость продукта. В условиях глобальной нестабильности цепочек поставок, способность производить чипы в больших объемах и без внешних рисков становится ключевым конкурентным преимуществом.
Но за эту доступность приходится платить. И плата эта - энергоэффективность. Чтобы достичь заявленной производительности в 25 TFLOPS в операциях FP32 на более старом техпроцессе, требуется больше энергии. Как следствие, мы видим внушительный TDP в 450 Вт у MTT S4000 против 400 Вт у A100 80GB PCIe. Это не просто цифра в спецификации, а ключевой архитектурный компромисс: производительность и доступность в обмен на более высокое энергопотребление и, как следствие, тепловыделение. Этот фактор необходимо учитывать при проектировании серверных стоек, систем охлаждения и расчете совокупной стоимости владения (TCO), особенно в крупных инсталляциях. Например, сервер с 8 такими GPU будет потреблять до 3.6 кВт только на ускорители, не считая CPU, памяти и других компонентов. Это требует мощных блоков питания, эффективных систем отвода тепла (возможно, жидкостного охлаждения для плотных стоек) и соответствующей инфраструктуры дата центра. Однако, если стоимость покупки GPU значительно ниже, то даже с учетом повышенных операционных расходов на электроэнергию, TCO может оказаться более выгодным на горизонте 3 - 5 лет, особенно для компаний, не имеющих доступа к флагманским решениям NVIDIA по адекватным ценам.
Архитектурный глубокий анализ: Копирование выигрышной формулы с китайским акцентом
Moore Threads не просто создали GPU, они создали MUSA - Moore Threads Unified System Architecture. Это не просто название для чипа, а идеология целой платформы, которая включает в себя архитектуру набора команд (ISA), программную модель, runtime библиотеки, драйверы и, собственно, физическую архитектуру чипа. Такой подход напрямую повторяет стратегию NVIDIA с CUDA, где успех определяется не только «железом», но и всей программной обвязкой. Это фундаментальное понимание того, что без полноценной экосистемы даже самое мощное «железо» останется невостребованным.
MTT S4000 построен на третьем поколении этой архитектуры под кодовым названием QuYuan и несет в себе чип под кодовым названием Chunxiao (Весенняя заря). Внутри этого чипа с 22 миллиардами транзисторов находятся 8192 так называемых ядер MUSA. Хотя компания не раскрывает детальную иерархию, по аналогии с другими GPU архитектурами можно предположить, что эти ядра сгруппированы в кластеры (аналоги Streaming Multiprocessor у NVIDIA), которые, в свою очередь, состоят из исполнительных блоков. Каждый такой кластер, вероятно, имеет свои собственные ресурсы: кэш память, планировщики потоков, блоки загрузки и выгрузки данных. Это стратегически верное решение, так как оно не изобретает велосипед, а идет по проверенному пути, создавая собственную, но концептуально знакомую инженерам параллельную архитектуру. Такая архитектура позволяет эффективно выполнять SIMT (Single Instruction, Multiple Threads) вычисления, где тысячи потоков одновременно выполняют одну и ту же инструкцию на разных данных, что является основой для ускорения нейронных сетей и HPC-задач.
Современный AI-ускоритель - это не только «голые» FP32-ядра. Его мощь определяется специализированными блоками, предназначенными для ускорения конкретных типов вычислений. И у MTT S4000 они есть:
● Тензорные ядра: Карта оснащена 128 тензорными ядрами нового поколения. Как и у NVIDIA, их задача - многократно ускорять операции матричного умножения (GEMM - General Matrix Multiply), которые являются основой большинства нейросетевых вычислений. Заявлена поддержка широкого спектра вычислительных точностей, включая FP64, FP32, TF32, FP16, BF16 и INT8.
● FP16 (Half-Precision Floating Point): Широко используется в обучении нейросетей для снижения требований к памяти и увеличения скорости вычислений, при минимальной потере точности. Для MTT S4000 базовая производительность FP16 составляет 25 TFLOPS, а с использованием тензорных ядер до 100 TFLOPS.
● BF16 (BFloat16): Формат, разработанный Google, который имеет тот же диапазон, что и FP32, но меньшую точность, что делает его более устойчивым к переполнению и не дополнению при обучении.
● TF32 (TensorFloat32): Представленный NVIDIA, этот формат использует диапазон FP32, но точность FP16, позволяя использовать тензорные ядра для FP32-подобных вычислений с высокой скоростью.
● INT8 (8-bit Integer): Используется преимущественно для инференса, так как позволяет значительно сократить размер модели и ускорить вычисления при минимальной потере точности.
Именно эти ядра обеспечивают внушительные цифры в 100 TFLOPS для FP16/BF16 и 200 TOPS для INT8, что делает карту релевантной для задач как обучения (особенно больших языковых моделей), так и инференса. Наличие специализированных ядер для каждого из этих форматов демонстрирует глубокое понимание Moore Threads современных требований к аппаратным ускорителям ИИ.
● Интерконнект MTLink: Возможно, самый важный с точки зрения архитектуры серверного решения элемент - это MTLink. Это проприетарный высокоскоростной интерконнект, прямой аналог NVIDIA NVLink, с заявленной общей пропускной способностью 240 ГБ/с. В частности, он включает MTLinkLO со скоростью 112 ГБ/с. Да, это медленнее, чем NVLink у A100 (600 ГБ/с) или H100 (900 ГБ/с). Однако сам факт его наличия - это огромный шаг вперед. Наличие любого проприетарного интерконнекта кардинально меняет правила игры по сравнению с использованием стандартной шины PCIe для коммуникации между GPU. PCIe 5.0 x16 обеспечивает около 128 ГБ/с двунаправленной пропускной способности, что является узким местом для масштабирования. MTLink же позволяет объединять несколько ускорителей (до 8 в сервере MCCX D800) в единый пул с прямым доступом к памяти друг друга. Для обучения больших языковых моделей, где требуется постоянный обмен градиентами, синхронизация весов и данных между GPU, это не просто приятный бонус, а критически важная технология. Она позволяет реализовать такие стратегии распределенного обучения, как Data Parallelism (распределение данных по GPU) и Model Parallelism (распределение частей модели по GPU), без значительных задержек. MTLink демонстрирует, что Moore Threads понимают архитектурные требования для построения серьезных AI-кластеров, предлагая прагматичное решение, делающее эффективное масштабирование возможным, даже если его пропускная способность пока не дотягивает до топовых решений NVIDIA. Это фундамент для создания конкурентоспособных многопроцессорных систем.
● Медиа-движок и рендеринг: MTT S4000 позиционируется как "полнофункциональный GPU для вычислений в мета вселенной". Это подкрепляется наличием мощных аппаратных декодеров и кодировщиков видео. Ускоритель способен одновременно декодировать до 48 потоков 1080p@30fps (AV1, H.264, H.265) или до 96 потоков 1080p@30fps (AV1, H.264, H.265, VP9, AVS2). Возможности кодирования также впечатляют: до 48 потоков 1080p@30fps. Это делает S4000 пригодным не только для AI вычислений, но и для видеоаналитики, транскодирования, облачного гейминга и стриминга. В дополнение к этому, заявлены высокие показатели рендеринга: 768 Гтекселей/с для текстурирования и 768 Гпикселей/с для пикселей, что важно для задач визуализации, цифровых двойников и создания контента для мета вселенных. Наличие 4x DP1.4a портов для вывода изображения также подчеркивает его универсальность.
● Безопасность и виртуализация: Для корпоративного сегмента и дата-центров критически важны функции безопасности и виртуализации. MTT S4000 оснащен MUSA Safety Engine 2.0 и поддерживает Trusted Execution Environment (TEE), что обеспечивает повышенную защиту данных и вычислений. В области виртуализации GPU реализованы функции динамического разделения и SR-IOV (Single Root I/O Virtualization). Это позволяет эффективно распределять ресурсы одного физического GPU между несколькими виртуальными машинами или контейнерами, обеспечивая изоляцию и предсказуемую производительность для каждого пользователя или приложения. Это делает S4000 гибким решением для облачных провайдеров и компаний, использующих виртуализированные среды.
● Форм-фактор: MTT S4000 выполнен в двухслотовом форм-факторе PCIe с размерами 266x112x39 мм, что является стандартным для серверных ускорителей и обеспечивает совместимость с большинством современных серверных платформ.
Программный стек: Битва за умы разработчиков и путь к независимости
Самое лучшее железо бесполезно без зрелого программного обеспечения. Все конкуренты NVIDIA разбивались именно об этот бастион. В Moore Threads это, очевидно, понимали, поэтому подошли к вопросу системно. В основе всего лежит MUSA SDK, который до боли напоминает структуру CUDA SDK, что является намеренным шагом для упрощения миграции:
● muDNN: GPU ускоренная библиотека для примитивов глубоких нейронных сетей (свертки, пулинг, нормализация, активации). Прямой аналог NVIDIA cuDNN. Она предоставляет высокооптимизированные реализации базовых операций, которые являются строительными блоками для любого фреймворка глубокого обучения. Без muDNN производительность фреймворков была бы неприемлемой.
● muFFT: Библиотека для быстрых преобразований Фурье. Аналог cuFFT. Важна для многих научных и инженерных приложений, а также для некоторых архитектур нейросетей, использующих частотную область.
● MCCL (Moore Threads Collective Communication Library): Библиотека для коллективных коммуникаций, необходимая для распределенного обучения. Аналог NCCL (NVIDIA Collective Communications Library). MCCL обеспечивает эффективный обмен данными между GPU (например, all-reduce, all-gather, broadcast), что критически важно для масштабирования обучения больших моделей на нескольких ускорителях. Оптимизация этих операций напрямую влияет на скорость обучения.
Но главный козырь - это инструменты миграции, призванные максимально упростить переход с CUDA-ориентированных фреймворков. Компания предлагает:
● torch_musa: Специальный пакет для PyTorch, который позволяет запускать существующий код с минимальными изменениями. torch_musa работает как бэкенд для PyTorch, перенаправляя вызовы к операциям на MUSA GPU. Это означает, что разработчикам достаточно изменить device='cuda' на device='musa' в своем PyTorch-коде, и большая часть функциональности будет работать "из коробки". Это значительно снижает порог входа и время на адаптацию.
● MUSIFY: Амбициозный инструмент для автоматической трансляции CUDA кода (написанного на C++ с использованием CUDA API) в MUSA совместимый код. Это более сложный уровень миграции, предназначенный для тех, кто использует кастомные CUDA ядра или низкоуровневые оптимизации. MUSIFY анализирует CUDA код и пытается преобразовать его в эквивалентные MUSA инструкции или вызовы API. Это сложная задача, и успешность зависит от сложности и специфики исходного CUDA кода.
● musa_converter: Для Python скриптов и PyTorch проектов, musa_converter может выполнять автоматическую замену строк и вызовов API, связанных с CUDA, на совместимые с MUSA. Это более высокоуровневый инструмент, чем MUSIFY, и он направлен на автоматизацию тех ручных правок, которые мы упоминали в предыдущей статье.
Здесь важно применить "гамбит честности". Технически грамотная аудитория, скорее всего, в курсе о невысоких результатах игровых карт Moore Threads, таких как MTT S80, в геймерских тестах. Игнорирование этого факта подорвало бы доверие. Поэтому стоит открыто признать: да, с оптимизацией драйверов под игровые API (DirectX, Vulkan) есть проблемы, и игровые карты Moore Threads пока не могут конкурировать с лидерами рынка. Однако необходимо сразу же сместить фокус: разработка драйверов для серверных вычислений (GPGPU, HPC, AI) и для игр - это две разные, независимые ветки разработки с разными приоритетами. Для игр важен универсальный API-интерфейс и оптимизация под широкий спектр движков. Для AI/HPC критична производительность в матричных операциях, стабильность работы с фреймворками глубокого обучения, эффективность коллективных коммуникаций и надежность в режиме 24/7.
Глубина проработки MUSA SDK и наличие специализированных библиотек для AI/HPC свидетельствуют о том, что именно серверное направление является приоритетным и более зрелым для Moore Threads. Этот подход превращает потенциальную слабость в демонстрацию честности и помогает сфокусировать внимание на сильных сторонах продукта для целевой аудитории, подчеркивая, что компания осознанно выбрала фокус на серверные решения.
Инженерный вердикт: Компетентный претендент с четкими компромиссами и стратегической ценностью
Итак, что мы имеем в сухом остатке? Moore Threads MTT S4000 - это не убийца A100 в прямом смысле слова, если речь идет о пиковой производительности на ватт или абсолютном лидерстве в бенчмарках. По чистой производительности на ватт он уступает флагманам NVIDIA, что неудивительно, учитывая разницу в техпроцессе и зрелости архитектуры.
Однако это и не «очередная поделка». Это на удивление целостная и продуманная платформа. Инженеры Moore Threads создали не просто чип, а всю вертикаль: от железа (GPU с тензорными ядрами и интерконнектом MTLink) до полного программного стека (MUSA SDK с muDNN, muFFT, MCCL), идеологически повторяющего CUDA. Осознание того, что главная преграда - это экосистема CUDA, привело к созданию ключевых инструментов миграции (torch_musa, MUSIFY, musa_converter), призванных максимально упростить переход.
Ключевые компромиссы ясны: доступность и более низкая цена покупки достигаются за счет более высокого энергопотребления (TDP 450 Вт) и потенциальной «сырости» молодого программного стека, который, несмотря на все усилия, пока не может похвастаться десятилетиями отладки и оптимизации, как CUDA. Тем не менее, для многих задач, особенно в условиях ограниченного бюджета и проблем с поставками, эти компромиссы могут быть вполне приемлемыми.
Когда MTT S4000 становится привлекательным?
● Экономическая эффективность: Если стоимость приобретения MTT S4000 значительно ниже, чем у NVIDIA A100, то даже при повышенных эксплуатационных расходах (электроэнергия, охлаждение), совокупная стоимость владения (TCO) может быть ниже. Это особенно актуально для стартапов, среднего бизнеса и исследовательских центров с ограниченным финансированием.
● Независимость поставок: В условиях геополитических рисков и санкций, наличие стабильного и предсказуемого канала поставок становится стратегическим преимуществом. Китайские GPU предлагают такую независимость.
● Специфические рабочие нагрузки: Для определенных задач, где требуется большой объем памяти (48 ГБ GDDR6) или где производительность в FP16/BF16/INT8 является ключевой, MTT S4000 может показать себя очень хорошо. Добавленные возможности по работе с видео и рендерингом делают его универсальным решением для задач, выходящих за рамки чистого AI обучения.
● Развитие собственной экспертизы: Использование альтернативных платформ способствует развитию внутренней экспертизы и снижению зависимости от одного вендора.
MTT S4000 - это серьезный и компетентный шаг в построении альтернативной AI экосистемы. Его архитектура не революционна, но она грамотно повторяет все то, что сделало NVIDIA лидером, при этом адаптируясь к реалиям производства и поставок. Для российского рынка, отрезанного от топовых решений, это не просто еще один GPU. Это возможность получить современную, масштабируемую архитектуру, созданную с явным прицелом на решение реальных AI задач, включая поддержку мета вселенных, видеообработки и повышенную безопасность. Главный вопрос переходит из плоскости «железа» в плоскость софта: насколько стабильно и предсказуемо все это будет работать на реальных задачах, и как быстро будет развиваться экосистема. Но с точки зрения инженерии, проделанная работа вызывает уважение. Это первый китайский GPU, на который действительно стоит обратить пристальное внимание как на жизнеспособную альтернативу в условиях новой реальности.