
MetaX C500 китайский GPU для ML-задач под санкционные реалии
11 марта 2026 г.
Разбираем архитектуру, спецификации и честные компромиссы GPU, который уже работает в российских продакшн окружениях.
Когда в 2022 году NVIDIA окончательно ушла с российского рынка, у ML команд осталось несколько сценариев: переплачивать за серые схемы, уходить в облака с западной инфраструктурой, или смотреть в сторону альтернатив. Один из самых зрелых вариантов сегодня - MetaX C500. Мы работаем с этим железом с момента первых поставок в Россию, тестировали его совместно с МФТИ на реальных ML пайплайнах. Вот что реально стоит знать.
Кто такой MetaX?
MetaX (читается «Мусси») - шанхайский стартап, основанный в сентябре 2020 года. За четыре года компания прошла путь от первого tape out до массового производства и выхода на биржу STAR Market в марте 2026 года.
Основатели - не случайные люди в полупроводниках. CEO Уильям Чен до MetaX возглавлял глобальное GPU подразделение AMD. CTO по железу Джесси Пэн - первая женщина-Fellow в AMD на глобальном уровне. CTO по программному обеспечению доктор Цзянь Ян - первый AMD Fellow в Большом Китае. Команда R&D насчитывает около 900 человек, из которых 80% - разработчики.
Это важно не ради биографических справок. Команда с бэкграундом AMD проектирует архитектуру иначе, чем стартапы, которые пытаются скопировать NVIDIA снизу вверх. Это чувствуется в C500.
Продуктовая линейка: куда вписывается C500
MetaX выпускает три серии GPU:
N-серия (Xisi) - гетерогенные GPGPU с выделенным блоком DLA, ориентированы на инференс. N100 - первый продукт компании, N260 закрывает задачи продакшн инференса LLM.
C-серия (Xiyun) - флагман общего назначения, обучение + инференс + вычисления. Сюда входит наш герой C500, а также C550 (OAM-формат), C500X (оптический интерконнект) и свежий C600.
G-серия (MXG100) - рендеринг и метавселенные, нас интересует меньше.
C500 - это основной рабочий конь C-серии. PCIe-карта, которую можно воткнуть в стандартный сервер. Именно её мы тестировали, именно она доступна на аренде у ChaiTex прямо сейчас.
Архитектура MXMACA: что внутри
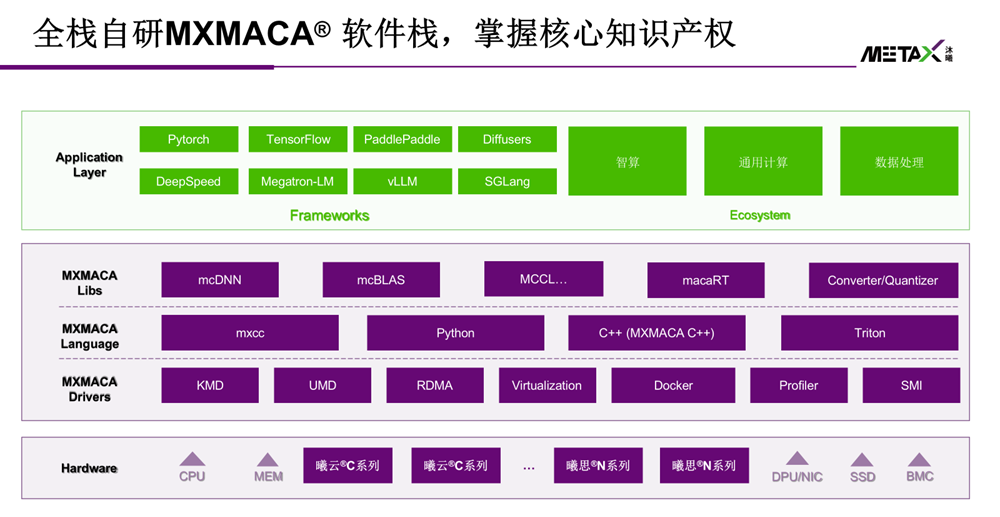
MetaX разработал собственную архитектуру GPGPU с нуля - они называют её MXMACA (MetaX Memory Access and Compute Architecture). Никакого лицензированного IP от ARM или Imagination Technologies. Полностью своя.
Ключевые архитектурные решения C500:
Вычислительное ядро построено на блоках AP (Arithmetic Processors), организованных в матрицу с общим L2 Cache и High Speed Fabric между блоками. Аналог Streaming Multiprocessors в NVIDIA терминологии, но с другой топологией.
Память - HBM2e, 64 ГБ. Это не GDDR6 и не GDDR7 - полноценная High Bandwidth Memory второго поколения с расширенными возможностями. Пропускная способность - 440 ГБ/с. Для сравнения: у A100 80GB - 2 ТБ/с (HBM2e), у A100 40GB - 1,6 ТБ/с. C500 здесь уступает, и это честный компромисс, о котором поговорим ниже.
Интерконнект - MetaXLink, проприетарный высокоскоростной интерфейс для связи карт между собой. Поддерживает режимы 2-карточного и 4-карточного PCIe соединения с пропускной способностью до 256 ГБ/с и 384 ГБ/с соответственно. В OAM конфигурации (C550) - до 896 ГБ/с при 8-карточном полном соединении.
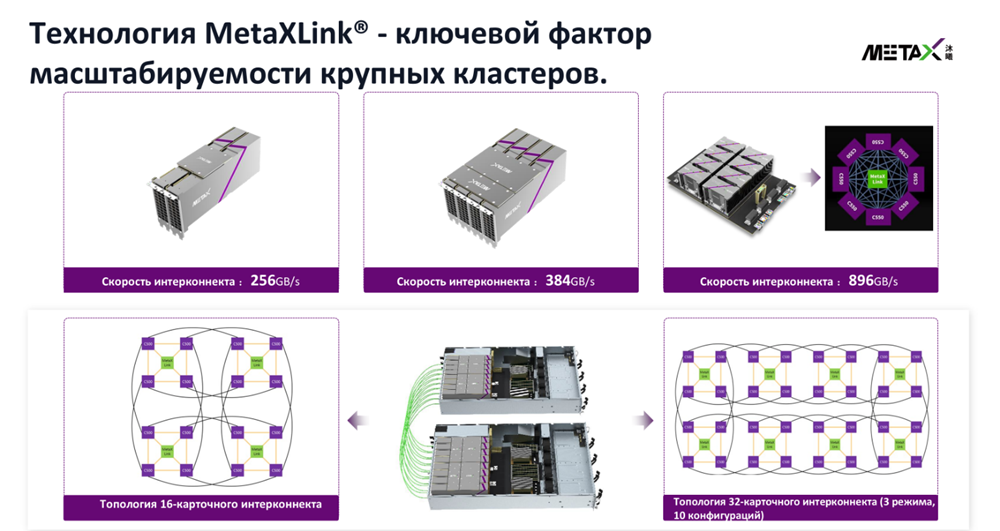
Хост-интерфейс - PCIe 4.0 x16. Да, четвёртое поколение, не пятое. В большинстве современных серверных платформ это не узкое место для ML-задач, но при интенсивном обмене с CPU нужно учитывать.
Технические характеристики: цифры без округления
Вот полная таблица производительности C500 на разных форматах данных:
Формат | Производительность |
FP32 (вектор) | 30 TFLOPS |
FP16 (вектор) | 240 TFLOPS |
TF32 Tensor | 120 TFLOPS |
FP16/BF16 Tensor | 240 TFLOPS |
INT8 Tensor | 480 TOPS |
FP64 - не указана производителем. Это говорит о том, что карта не ориентирована на HPC задачи с двойной точностью. Для LLM обучения и инференса это несущественно, для научных расчётов типа молекулярной динамики - нужно проверять отдельно.
TDP - 350 Вт. Поддерживаются и воздушное, и жидкостное охлаждение.
Что получаете в сборке сервера на 8xC500

Стандартная серверная конфигурация на базе C500 выглядит так:
GPU: 8× MetaX C500 64ГБ = 512 ГБ суммарной HBM2e-памяти
CPU: 2× Intel Xeon Gold 6530 (32 ядра / 160 МБ кэша / 270 Вт каждый) - итого 64 физических ядра, 128 потоков
RAM: 1 ТБ DDR5-4800 ECC RDIMM (16× 64 ГБ)
Хранилище: 2× 7,68 ТБ PCIe Gen4 NVMe + 2× 480 ГБ SATA SSD
Сеть: 2× 400 Гбит/с (PCIe 5.0) + 2× 25 Гбит/с SFP28
Питание: 4× 2700 Вт Platinum
Форм-фактор: 4U
Виртуализация: поддерживается vGPU через SR-IOV
Суммарная FP16-производительность сервера: 8 × 240 = 1920 TFLOPS
Для сравнения: сервер на 8× A100 80GB даёт около 2400 TFLOPS FP16. C500-сервер - примерно 80% от этого значения при кратно меньшей цене на рынке.
Программный стек MXMACA: главный вопрос о совместимости
Любой, кто сталкивался с не NVIDIA GPU, знает: железо - это полдела. Программная совместимость решает всё.
MetaX подошли к этому системно. MXMACA-стек по архитектуре зеркалит CUDA:
На уровне языка: MXMACA C++ (аналог CUDA C++), Python, поддержка OpenCL и Triton;
На уровне библиотек: mcDNN (≈ cuDNN), mcBLAS (≈ cuBLAS), MCCL (≈ NCCL для коллективных операций), macaRT (≈ TensorRT);
На уровне фреймворков: PyTorch, TensorFlow, PaddlePaddle, MindSpore, DeepSpeed, Megatron-LM, vLLM, SGLang;
На уровне инфраструктуры: KMD/UMD-драйверы, RDMA, Docker, Profiler, SMI.
Ключевая цифра - PyTorch-совместимость по операторам: более 2200 операторов, покрытие 100% по заявлению производителя. Для сравнения, у большинства других китайских GPU этот показатель в диапазоне нескольких сотен - тысячи операторов.
Отдельный важный момент: поддержка Flash Attention. Это алгоритмически критичный оператор для трансформерных архитектур, который многие китайские GPU либо не поддерживают вообще, либо поддерживают частично. У C500 - полная поддержка.
В июне 2025 года MetaX открыл исходный код MXMACA. Это важный сигнал: компания ставит на экосистему, а не на закрытый стек.
Эволюция совместимости: хронология
MetaX публично показывает, как росла MXMACA совместимость:
2022.06: 400 сторонних тест-кейсов;
2022.10: 1752 открытых репозитория;
2023.08: 2000 приложений (бета-тест);
2023.10: 3000 приложений (альфа-релиз);
2024.12: 6000 открытых проектов верифицированы;
2025.06: MXMACA полностью открыта.
Это не статичная картина. Стек активно развивается, и новые версии PyTorch MetaX начинает поддерживать примерно за одну неделю после релиза. У большинства конкурентов - несколько месяцев.
Что реально работает, а что нет
Скажем честно, потому что проверяли на практике.
Работает хорошо:
PyTorch-пайплайны обучения трансформеров без переписывания кода;
LLM-инференс через vLLM и SGLang;
Distributed training через DeepSpeed и Megatron-LM;
Большинство CUDA-проектов после смены переменных окружения - фактически один шаг.
Работает с нюансами:
Кастомные CUDA-ядра требуют портирования на MXMACA C++ (0,5–3 дня по оценке MetaX, в нашей практике - зависит от сложности);
JAX - поддержка ограничена, нужно уточнять под конкретные задачи;
Специфические версии библиотек с жёсткой привязкой к CUDA API могут требовать тестирования.
Не проверяли:
Задачи с интенсивным FP64 (молекулярная динамика, CFD);
Приложения, использующие CUDA Graph напрямую;
Кластерные показатели: данные MetaX.
Для тех, кто думает про масштаб - MetaX публикует данные по производительности кластера на реальных задачах:
Обучение 128B параметровой модели на кластере 1024 карт (C550, OAM версия):
Линейность масштабирования: 95% (по заявлению, выше международных аналогов для Dense моделей).
Непрерывное обучение: 45 дней без сбоев
MFU (Model FLOP Utilization): >65%
MTTR (среднее время восстановления после сбоя): <15 минут - диагностика до 5 минут, восстановление до 10 минут.
Эффективное время обучения: 98,6% с учётом всех сбоев и checkpoint-пауз
Это данные производителя, не независимый бенчмарк. Принимаем с соответствующей поправкой. Но порядок цифр - рабочий.
Реальные клиенты MetaX: кто уже развернул
Это не гипотетические кейсы - это задокументированные коммерческие поставки:
(China Merchants Bank): в январе 2025 года партнёр MetaX выиграл тендер на 39 серверов = 312 карт C500 для задач LLM и генерации контента;
(Hospital Zhongshan): медицинские AI-приложения, мультимодальный анализ, 40 000 диагностических процедур в год;
(China Southern Power Grid): оптимизация диспетчеризации, параллельные вычисления для решателей;
(Zhejiang University): 35 серверов = 280 карт C550 для AI кафедры и стартапов при университете
(GAC Group): 10 серверов = 80 карт C500 для разработки систем автопилота, смешанное обучение с международными GPU
(Xinhua News Agency): кластер MetaX в Пекине для LLM новостного ассистента
Сравнение с NVIDIA: где разрыв, а где нет
Попытаемся быть точными, а не просто дешевле NVIDIA.
Параметр | MetaX C500 | NVIDIA A100 80GB |
FP16 Tensor | 240 TFLOPS | 312 TFLOPS |
BF16 Tensor | 240 TFLOPS | 312 TFLOPS |
INT8 | 480 TOPS | 624 TOPS |
VRAM | 64 ГБ HBM2e | 80 ГБ HBM2e |
Память BW | 440 ГБ/с | 2 ТБ/с |
Интерконнект BW | 256–384 ГБ/с | 600 ГБ/с (NVLink) |
TDP | 350 Вт | 400 Вт |
Самое заметное отставание - пропускная способность памяти. 440 ГБ/с против 2 ТБ/с у A100. Это критично для задач, bottleneck которых - bandwidth: авторегрессионный инференс длинных контекстов, некоторые операции с большими батчами.
Для задач, bottleneck которых - compute (предобучение LLM на коротких контекстах, файнтюнинг), разрыв значительно меньше и определяется 240 TFLOPS против 312 TFLOPS - около 77%.
DeepSeek на C500: конкретные конфигурации
MetaX опубликовал матрицу конфигураций для DeepSeek-R1/V3, которая показывает, как позиционируется C500 в реальных задачах:
Задача | Конфигурация | Модель |
DeepSeek R1/V3 671B инференс INT8 | 16× C500 / 2 сервера | Удовлетворительно |
DeepSeek R1/V3 671B инференс полный | 32× C500 / 4 сервера | Полная точность |
DeepSeek R1/V3 обучение + инференс | 384× C500 / 48 серверов | Кластерная задача |
Модели до 70B инференс + файнтюнинг | 8× C500 / 1 сервер | Рабочий вариант |
Одиночная карта N260 (инференс-версия) тянет R1/V3 671B целиком через квантизацию - это отдельный продукт для тех, кому нужен персональный DeepSeek.
Для кого C500 имеет смысл
C500 - рабочее решение, а не временная заглушка, если ваши задачи укладываются в следующий профиль:
Подходит хорошо:
Обучение LLM среднего размера (до 70B) на стандартных PyTorch-пайплайнах;
Продакшн инференс с умеренным контекстом;
Файнтюнинг на базе открытых моделей;
Команды, которым нужна независимость от западной цепочки поставок;
Пилоты с возможностью арендовать до покупки.
Стоит дополнительно проверить:
Инференс с очень длинным контекстом (bandwidth-bottleneck);
Задачи с кастомными CUDA-ядрами (нужна оценка объёма портирования);
FP64-вычисления.
Не подходит:
HPC с интенсивным FP64;
Задачи с жёсткой привязкой к CUDA специфичным функциям без бюджета на портирование;
Попробовать C500 на своих задачах можно удалённо - у ChaiTex есть серверы в аренде.
Это разумный способ проверить совместимость своего стека до того, как принимать решение о покупке.
Если у вас есть конкретный ML стек и вопрос ляжет ли на C500 - пишите, разберём. Особенно интересен опыт тех, кто мигрировал с CUDA зависимых кастомных операторов.